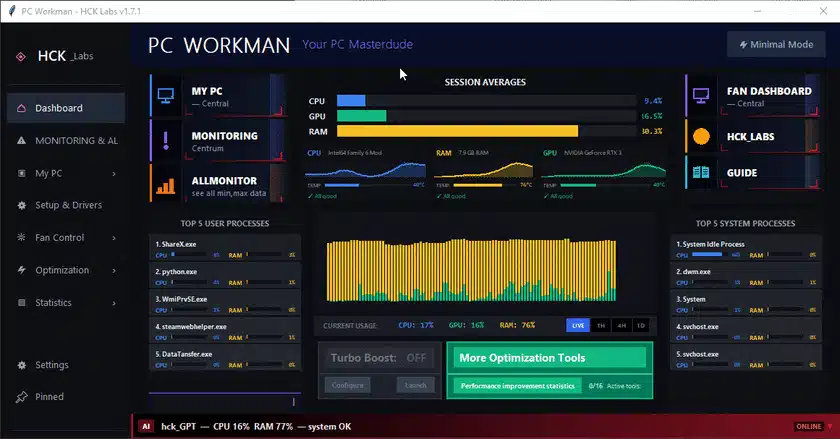
The Problem with Session-Only AI
In Part 1, hck_GPT had session memory—a Python dict that dies when the app closes. Useful for "we talked about RAM 3 messages ago," useless for "your GPU is an RTX 3060 with 6GB VRAM." That fact shouldn't require re-scanning every launch.
Part 2 solves this with three systems: a persistent knowledge base, a metrics store, and a proactive monitor. All offline. All local.
1. Persistent Knowledge Base: SQLite Tables with Purpose
The knowledge base uses four SQLite tables, each with a distinct job:
hardware_profile: Stores rarely-changing hardware info (CPU model, GPU name, VRAM, etc.). Scanned once viapsutil+ WMI, then cached. Ahardware_is_fresh()method checks if the last scan was within 24 hours—skips re-scan on startup.usage_patterns: Stores slowly-changing metrics like average CPU load, peak hours, top apps, detected use-case ("gaming" vs "development"). Updated periodically from the stats engine.user_facts: Stores inferred or user-stated facts (preferred language, PC usage type). Each fact has a confidence score—detected facts start at 1.0, inferred facts can be lower. This is how hck_GPT knows to greet you in Polish without asking every session.conversation_log: Keeps the last 500 messages across sessions (pruned monthly). Not for replaying conversations, but for pattern detection (e.g., "User asks about temperature every Monday").
On every AI response, a build_knowledge_summary() method injects hardware and user facts into the Ollama prompt. The LLM never needs to ask "what GPU do you have?"—it already knows from the first message.
2. Metrics Store: 90 Days of Hardware History
Every 5 minutes, a background thread snapshots 20+ sensor values into a deepmonitor_snapshots table. The table includes CPU load, temperature, frequency, power; GPU temperature, load, VRAM percentage; RAM and swap percentages; motherboard voltages; and disk usage (stored as JSON).
CREATE TABLE IF NOT EXISTS deepmonitor_snapshots (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ts REAL NOT NULL,
date_str TEXT NOT NULL,
cpu_load REAL,
cpu_temp REAL,
cpu_mhz REAL,
cpu_power REAL,
gpu_temp REAL,
gpu_load REAL,
gpu_vram_pct REAL,
gpu_power REAL,
ram_pct REAL,
swap_pct REAL,
mb_temp_sys REAL,
mb_volt_12v REAL,
mb_volt_5v REAL,
mb_volt_33v REAL,
disk_json TEXT
);
Retention is 90 days, with auto-prune after every snapshot. The database stays around 5-10 MB per month.
On startup, _load_historical_baselines() loads 7-day min/max/avg baselines into live memory. From the very first message, hck_GPT can say "your CPU is at 67%—but your 7-day average is 28%, something is off." Not because it guessed, but because it has 2,016 data points (288 snapshots/day × 7 days).
The public API is minimal—two methods cover 90% of use cases:
rows = metrics_store.get_history(hours=24) # raw snapshots
summary = metrics_store.daily_summary(days=7) # per-day aggregates
3. Proactive Monitor: AI That Speaks First
A daemon thread runs every 45 seconds, checks system state, and pushes alerts to the chat panel without user input. Seven conditions are monitored:
- CPU sustained high (>85% for two consecutive checks)
- CPU critical (>95%, immediate alert)
- RAM high (>88%, suggests checking what's eating memory)
- RAM critical (>93%, pagefile getting hit)
- CPU throttling (frequency ratio <60%, thermal limiting)
- Disk nearly full (any partition <4 GB free)
- Long session (PC running for many hours, gentle reminder)
Each alert has a bilingual message pool (Polish and English) with slight variations to avoid repetition:
_MSGS = {
"cpu_high": {
"en": [
"hck_GPT: ⚠ CPU sustained at {val}%. Type 'top processes' to see who's responsible.",
"hck_GPT: CPU {val}% — something's eating it. Type 'top' to find out what.",
],
"pl": [
"hck_GPT: ⚠ CPU na {val}% od dłuższego czasu. Wpisz 'top procesy' żeby zobaczyć winowajcę.",
"hck_GPT: CPU {val}% — coś go zjada. Jeśli to nie Ty, to kto? Wpisz 'top'.",
],
},
}
Anti-spam is critical: a 5-minute gap between same alert types prevents flooding. The push mechanism uses callbacks scheduled on tkinter's main thread via root.after(0, ...), avoiding race conditions.
4. Bilingual Vocabulary: 854 Lines, No Translation API
Part 1 mentioned Polish and English patterns are "defined separately." Here's what that looks like at scale. vocabulary.py is 854 lines with 25+ intents. Each intent has a list of trigger patterns in both languages, mixed together without translation steps:
INTENT_PATTERNS = {
"hw_cpu": [
# Polish tokens
"procesor", "rdzeń", "rdzenie", "taktowanie",
# English tokens
"cpu", "processor", "cores", "boost",
# Polish multi-word (high bonus)
"jaki procesor", "jaki mam procesor", "ile rdzeni",
# English multi-word
"what cpu", "my cpu", "which processor",
],
}
Scoring: multi-word phrases get len(words) * 1.5 bonus, exact single tokens get 1.0, partial prefixes get 0.4, then normalized to min(1.0, score / 3.0). The vocabulary file IS the tuning knob—no hyperparameters, just patterns to add.
This week, 12 new intents were added from LinkedIn follower questions: battery_drain, session_compare, pc_changes, startup_safety, browser_cache, swap_analysis, network_usage—each with 10-20 patterns in both languages.
Putting It Together
Part 1 gave you intent parsing, 9-layer routing, and a hybrid rule/LLM engine. Part 2 adds long-term memory (SQLite knowledge base), historical context (metrics store with 90-day retention), and proactive alerts. The result is an AI that remembers your hardware, knows your habits, and warns you about problems before you notice them—all offline, all local.





