Liquid AI Ships LFM2.5-8B-A1B: A 1B Active Parameter MoE for Edge Devices
Liquid AI today released LFM2.5-8B-A1B, a Mixture-of-Experts (MoE) language model with 8 billion total parameters but only 1 billion active per token. It's designed to run on consumer hardware—laptops, phones, and single GPUs—while delivering strong performance on instruction following and agentic tasks. The model was pretrained on 38 trillion tokens, up from 12T in the previous LFM2-8B-A1B, and includes a 128K context window (up from 32K).
Architecture and Training Details
The model uses the same MoE+GQA+gated short convolution blocks as its predecessor, but with two key changes: it's now a reasoning-only model (producing an explicit chain-of-thought before answers), and the vocabulary size was doubled from 65,536 to 128,000. The tokenizer expansion was done by continuing BPE merge training on a multilingual corpus, preserving existing token IDs and initializing new embedding rows as the mean of their sub-token decompositions. This improved chars/token significantly for non-Latin languages: Hindi +120%, Thai +238%, Vietnamese +118%, Arabic +39%.
Context extension was a two-stage process: first to 32K with 2T tokens of reasoning/math/tool-use data, then to 128K by increasing the RoPE base frequency and training on 400B additional tokens of long-document and long-trajectory data.
Hallucination Reduction via RL
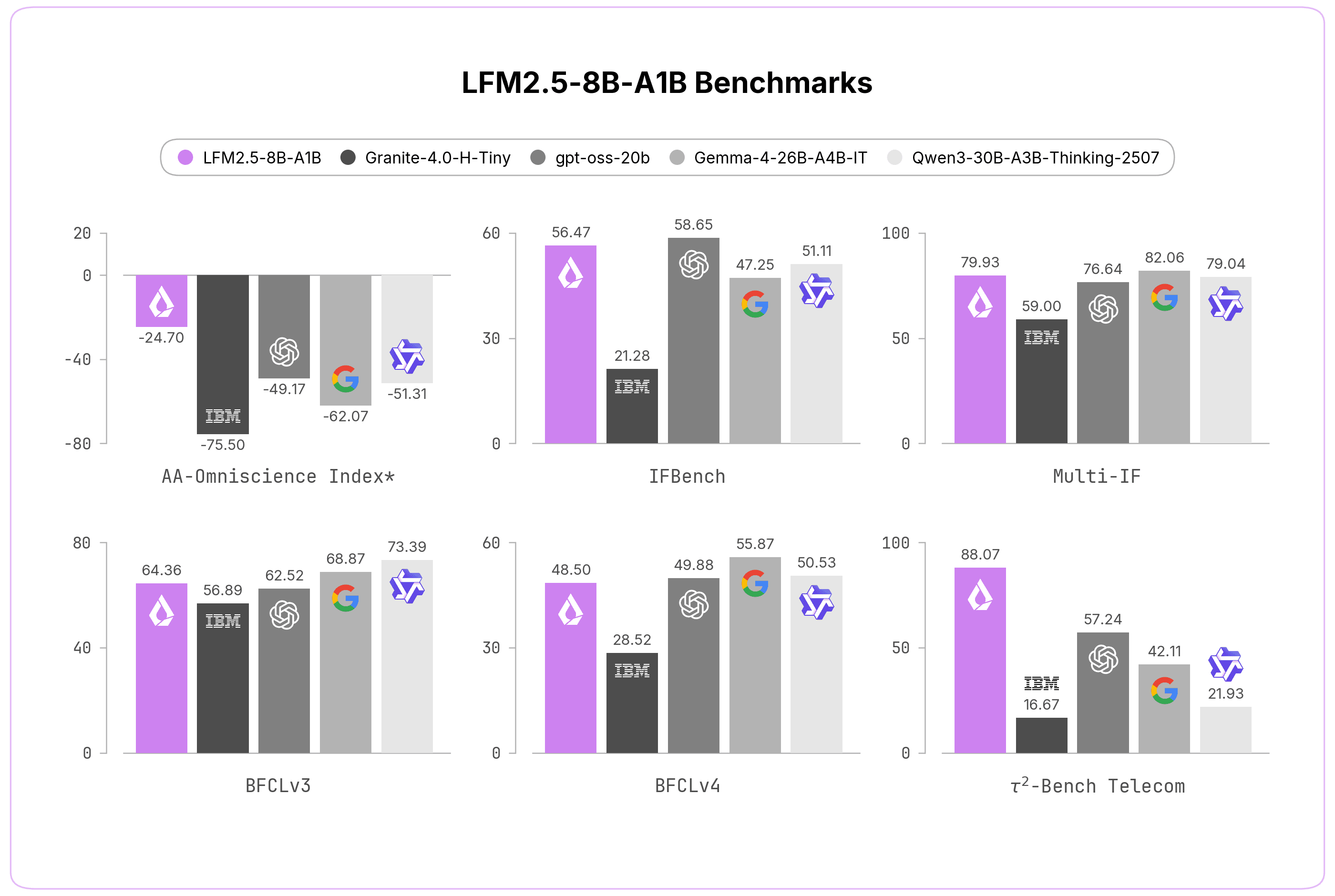
A standout feature is the targeted reinforcement learning stage to reduce hallucinations. Liquid used an avg@k-based reward over a diverse knowledge dataset, rewarding the model for abstaining on queries it can't reliably answer. This produced a sharper knowledge boundary. The non-hallucination rate on the AA-Omniscience benchmark jumped from 7.46% (LFM2-8B-A1B) to 63.47%—a 56 percentage point improvement. Accuracy also increased from 7.33% to 8.67%.
Benchmarks: Competitive with Larger Models
On instruction following, LFM2.5-8B-A1B scored 91.84 on IFEval, beating Qwen3-30B-A3B (90.82) and Gemma-4-26B-A4B (91.40). On Multi-IF it scored 79.93, again competitive with much larger MoEs. On MATH500 it hit 88.76, and on AIME25 it scored 42.53—lower than Qwen3-30B (71.67) but strong for its size.
On agentic benchmarks, it excelled at Tau² Telecom (88.07) and BFCLv3 (64.79), outperforming Granite-4.0-H-Tiny and Gemma-4 variants. The model is particularly strong on tool-calling tasks, which aligns with its design as an on-device personal assistant.
Inference Performance: Fast on CPU and GPU
LFM2.5-8B-A1B achieves 253 tokens/s on an Apple M5 Max and 146 tokens/s on an AMD Ryzen AI Max+ 395, using llama.cpp with under 6GB memory. On a phone it sustains ~30 tokens/s. On a single H100 GPU, it reaches 18.5K output tokens/s at high concurrency (1.6B tokens/day). Day-one support includes llama.cpp, MLX, vLLM, SGLang, and ONNX.
Getting Started
Download the base and post-trained models from Hugging Face. To run locally with llama.cpp:
# Download GGUF from Hugging Face
wget https://huggingface.co/liquid-ai/LFM2.5-8B-A1B-GGUF/resolve/main/lfm2.5-8b-a1b-q4_k_m.gguf
# Run with llama.cpp
./llama-cli -m lfm2.5-8b-a1b-q4_k_m.gguf -p "Call the get_weather tool for San Francisco" -n 256
For GPU serving with vLLM:
vllm serve liquid-ai/LFM2.5-8B-A1B --tensor-parallel-size 1 --max-model-len 8192
Liquid also released LocalCowork, an open-source desktop agent demo that runs entirely on-device with 67 tools across 13 MCP servers.
What's Next
Liquid AI positions this model as a step toward fully private, on-device agents. The combination of small active parameters, large context, and RL-tuned reliability makes it a practical choice for developers building local AI assistants. Try it on your laptop today.