The Mysterious Rise of Hy3
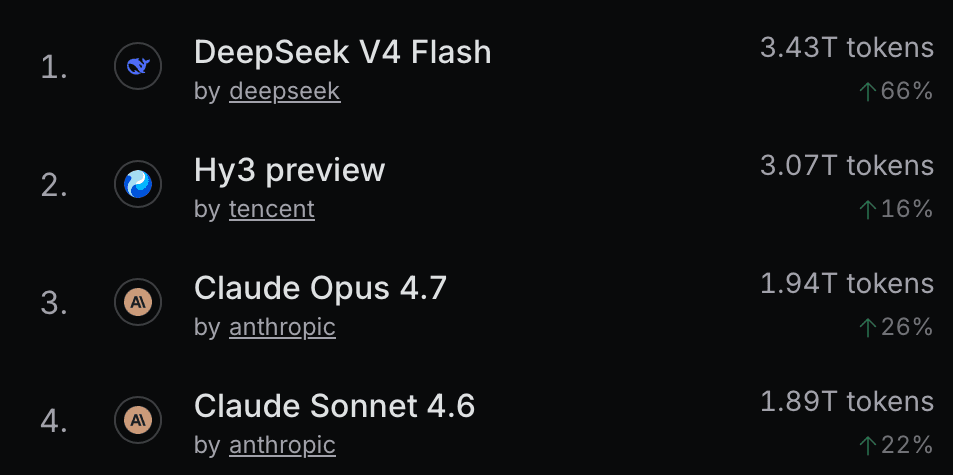
OpenRouter's AI Model Rankings show two models beating Claude in token usage by over 50%: DeepSeek Flash V4 and Hy3 preview. DeepSeek Flash V4 is a known open-source model with strong performance at low cost. Hy3 preview, however, is a mystery. Released by Chinese megacorp Tencent, its Hugging Face page is sparse and shows unimpressive benchmark results compared to other Chinese open-source models. A Hacker News search returns only one unrelated submission. Reddit discussions focus on its open-weights release, with a thread noting the model was free on OpenRouter until May 6, after which it became paid.
Despite this, Hy3 preview's usage has remained steady after the free period ended. On May 25, 2026, it was still ranked #2 by token usage. The model costs $0.066/1M input tokens, cheaper than DeepSeek V4 Flash's $0.10/1M. But quality is not on par with Claude Opus 4.7 or GPT 5.5. So why the popularity?
Data-Driven Investigation
OpenRouter's detailed data reveals that Hy3 preview's usage is organic—not a one-off spike from a single app switching defaults. The top 5 apps account for less than 1% of its activity. The model is served by only one provider: Singapore-based SiliconFlow. Before Hy3, SiliconFlow had little usage; after, it spiked. The transition from free to paid did not cause a drop, suggesting users find value.
The Real Cost of LLMs: Cache Economics
LLM API calls are stateless. Each turn reprocesses all tokens in the conversation, making input tokens dominate costs. For agentic workflows, input tokens can be 98% of total tokens. Providers implement prompt caching to reuse previously processed tokens, passing savings to customers. Most providers charge 10% of input cost for cache reads (OpenAI, Anthropic, Google). For DeepSeek V4 Flash, most providers charge 20%–50%—except DeepSeek itself.
DeepSeek's own provider charges a mere 2% cache read cost for DeepSeek V4 Flash, thanks to a new KV caching approach introduced with V4. The Pro variant has a cache read cost of 0.83%. This drastically reduces the effective price. OpenRouter now shows effective pricing tables on model pages. For DeepSeek V4 Flash via DeepSeek, the effective price is $0.018/1M input tokens. Hy3 preview via SiliconFlow has a 44% cache read cost, yielding an effective price of $0.034/1M. DeepSeek V4 Flash is nearly half the price.
Why Not Switch?
Given the cost advantage, why is Hy3 more popular? One reason: some developers may not want to route data through DeepSeek, a Chinese company with a data policy that includes training on prompts. Another: OpenRouter's automatic routing may not always select DeepSeek as provider; some clients may not support explicit provider selection. Subscription services like Claude Code or Codex are still better for heavy users, but for pay-as-you-go, DeepSeek V4 Flash via DeepSeek is the cheapest option.
Conclusion
The mystery of Hy3's popularity likely boils down to a single large app using it as a data-processing backbone, not an agentic coding app. But with the effective price data now public, expect a shift. Check OpenRouter's effective pricing table for your model. If you can use DeepSeek directly, you'll save over 50% compared to Hy3.
# Example: query DeepSeek V4 Flash via OpenRouter with explicit provider
curl https://openrouter.ai/api/v1/chat/completions \
-H "Authorization: Bearer $OPENROUTER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek/deepseek-v4-flash",
"provider": {"order": ["DeepSeek"]},
"messages": [{"role": "user", "content": "Hello"}]
}'