DuckDB: The Fastest Database You've Never Heard Of (Until Now)
DuckDB has gone from a research project at CWI Amsterdam in 2019 to one of the most widely adopted databases of the past decade. It powers notebooks, ETL pipelines, dashboards, and even an iPhone running TPC-H at scale factor 100. Companies like MotherDuck, Hex, Omni, Evidence, Fivetran, and Rill build products around it. At Greybeam, we use it for millions of queries per day.
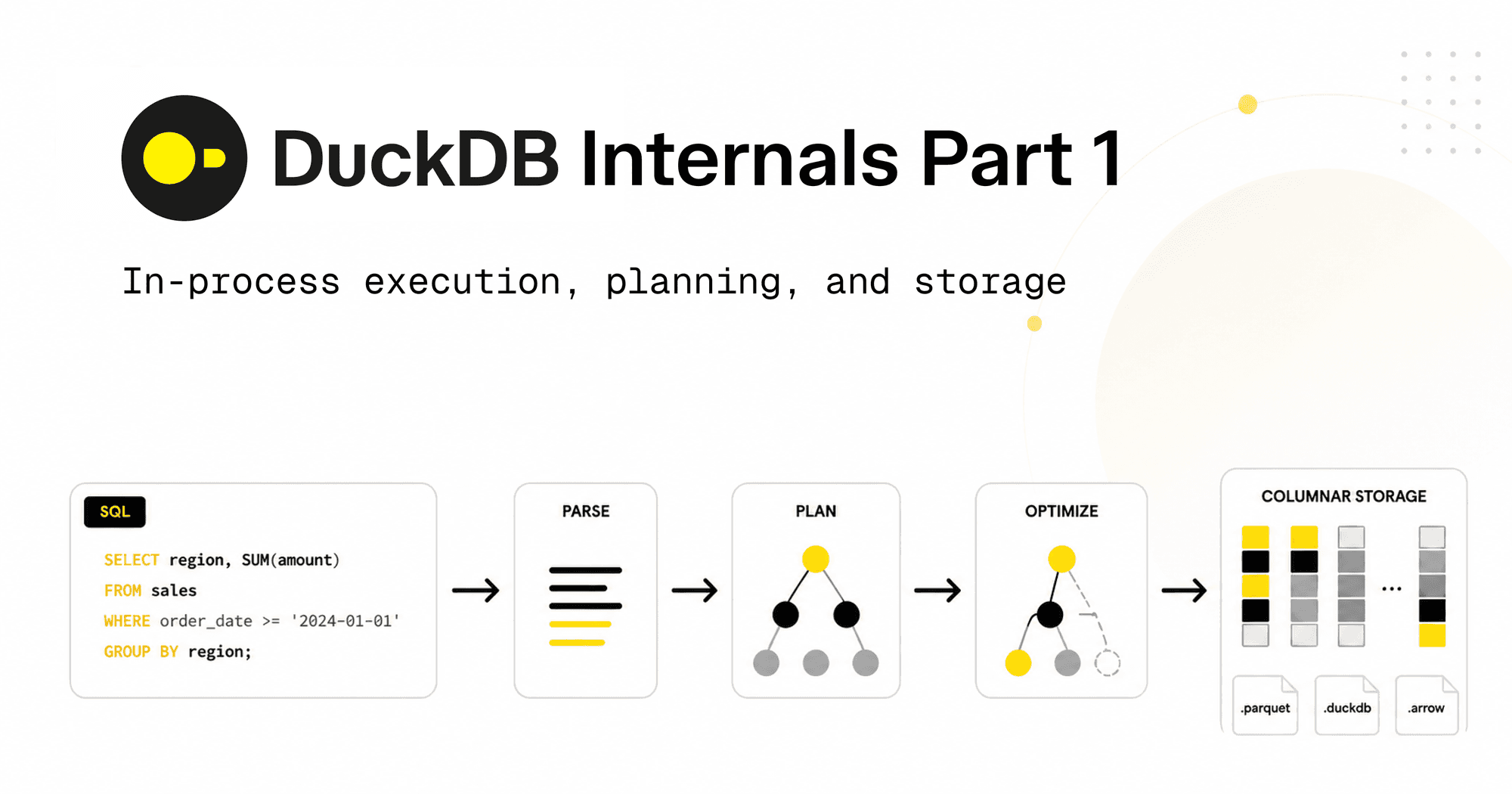
Why is DuckDB so fast? The answer lies in a handful of design choices: in-process execution, columnar compressed storage with zonemaps, vectorized execution, morsel-driven parallelism, and snapshot isolation with optimistic MVCC. This first post covers the query path from SQL to logical plan, plus the storage layer. Part 2 will cover query execution.
In-Process Execution Eliminates Serialization Overhead
Most analytical databases are servers: Snowflake, Postgres, BigQuery, Redshift. You send SQL over TCP, and results are serialized into a wire protocol, transmitted, and deserialized. Every value gets touched multiple times.
DuckDB is not a server. It's a library. You load libduckdb into your program and call functions directly. There's no network overhead.
In 2017, Mark Raasveldt and Hannes Mühleisen published "Don't Hold My Data Hostage," measuring that client protocols like ODBC and JDBC were often the slowest step in the entire query — sometimes dwarfing compute time. Two costs drive this: bandwidth (a gigabit link caps at ~125 MB/s) and per-value overhead (ODBC/JDBC make a function call per field per row — hundreds of millions of calls for a 100-million-row result).
DuckDB sidesteps both by living in the same process. When querying a pandas DataFrame, DuckDB uses a replacement scan to read the same buffers Python owns — zero-copy in the best case. Arrow is the cleanest version because it's already a columnar, typed memory format. Returning results as Arrow avoids row-by-row conversion.
From SQL to Logical Plan
Once SQL reaches DuckDB, it goes through: parse, bind, plan, optimize.
Parsing
DuckDB uses a fork of the Postgres parser, which is why its dialect feels familiar. Parsing turns SELECT sum(l_quantity) FROM lineitem WHERE l_shipdate > '2024-01-01' into an abstract syntax tree (AST). Here's the AST from SQLGlot:
Select(
expressions=[
Sum(
this=Column(
this=Identifier(this=l_quantity, quoted=False)))],
from_=From(
this=Table(
this=Identifier(this=lineitem, quoted=False))),
where=Where(
this=GT(
this=Column(
this=Identifier(this=l_shipdate, quoted=False)),
expression=Literal(this='2024-01-01', is_string=True))))
Binding
Binding resolves every name against the catalog. lineitem becomes a specific table with a known schema. l_quantity becomes a specific column with a known type. sum becomes a specific aggregate function. Type coercions happen here too.
Optimizer
DuckDB's optimizer consists of 33 small, focused transformations. You can inspect and disable them individually:
SELECT * FROM duckdb_optimizers();
Notable optimizers:
- Filter pushdown: Move WHERE predicates as close to the scan as possible so data is pruned early.
- Subquery unnesting: Rewrite correlated subqueries as joins, avoiding per-row execution.
- Dynamic join-filter pushdown: During hash join, compute min/max of join key values on the build side, then push those bounds into the probe-side scan as runtime filters. If the build side has fewer than 50 distinct values, it becomes an IN list instead of a range, skipping even more rows.
- Join order optimization: The order in which joins run determines intermediate result sizes. A 6-table join has 30,240 possible orders — DuckDB picks a good one.
Columnar Storage and Zonemaps
DuckDB stores data column by column, not row by row. This is critical for analytical queries that scan millions of rows but only touch a few columns. Columnar storage also enables better compression because values in a column are often similar.
Each column is divided into row groups (default ~122,880 rows). Each row group stores statistics (min, max, null count) called zonemaps. When a query filters on a column, DuckDB checks the zonemaps to skip entire row groups that cannot contain matching rows. This is why SELECT * FROM 'orders.parquet' WHERE l_shipdate > '2024-01-01' can return sub-second results on a 6 GB file — it doesn't read the whole file.
Why This Matters
DuckDB is redefining what's possible with single-node analytics. It holds its own against clusters costing millions per year. For developers building data-intensive applications, understanding DuckDB internals means you can optimize queries, choose the right data formats, and avoid common pitfalls.
What's Next
Part 2 will cover vectorized execution and morsel-driven parallelism — the engine that actually runs your queries. Subscribe to Greybeam's blog to get it.


