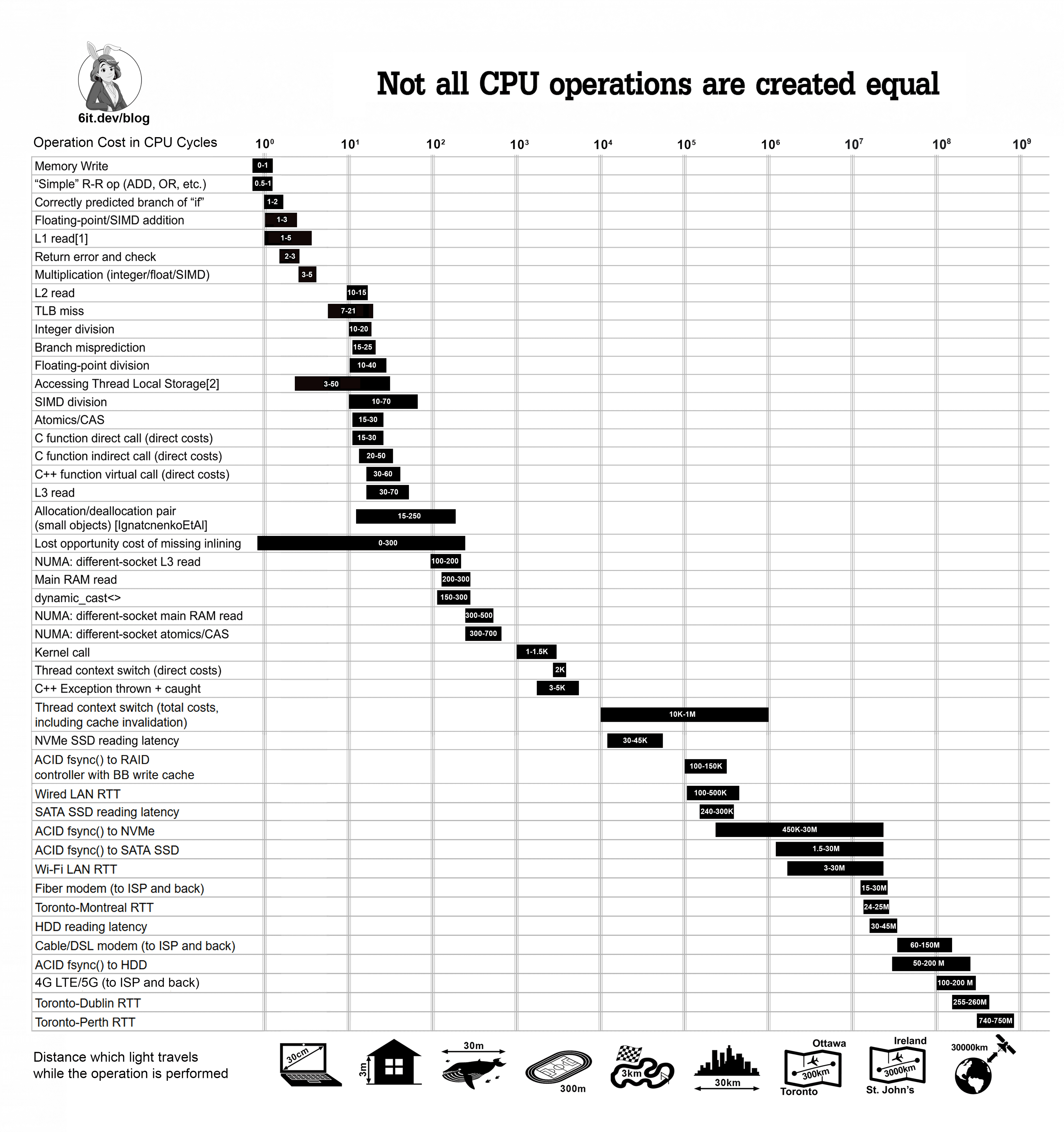
Division Still Hurts, But Less Than Before
Modern CPUs have improved division latency dramatically, but it's still the slowest arithmetic operation. According to the article, on Skylake-X (2017) a 64-bit integer division (IDIV) took 37-96 cycles. By Alder Lake-P (2021) that dropped to 14-18 cycles, and on Zen 4 (2022) it's 9-19 cycles. That's a 4-5x improvement, but still 9x slower than a multiplication (3 cycles).
Multiplication, on the other hand, is nearly free: 3 cycles for both 32-bit and 64-bit on most recent cores, except some E-cores where 64-bit multiply takes 5 cycles.
RTTI: dynamic_cast Can Be 5x Slower Than Virtual Calls
The article warns that dynamic_cast<> can be up to 5x more expensive than a simple virtual function call. However, RTTI doesn't increase object size — it reuses the existing vfptr for polymorphic classes. The cost is in code size and runtime lookup.
C++ Exceptions: Zero-Cost When Not Thrown
Contrary to outdated claims (Fog04), modern compilers implement "zero-cost exceptions" using a table approach, not stack-frame unwinding info. The cost of throwing an exception is around 2,700-5,000 cycles per [Nayar] and [Ongaro]. Compare that to returning an error code, which costs only ~2 extra cycles. The breakeven point: if exceptions occur less than once per 10,000 calls, exceptions win.
Atomics: CAS at ~15 Cycles, But Multi-Socket Can Hit 600
Compare-and-swap (CAS) costs about 15 cycles on a single socket. On multi-socket NUMA systems, that can balloon to 300-600 cycles. Worse, atomics prevent instruction-level parallelism, reducing bandwidth up to 30x compared to simple writes (SchweizerEtAl).
Function Calls: 15-30 Cycles Direct, 30-60 for Virtual
Direct function calls cost 15-30 cycles; indirect calls via function pointer cost 20-50 cycles; virtual calls cost 30-60 cycles. These numbers are from the authors' experience and consistent with Ruskin's observations.
Inlining eliminates those costs and enables cross-function optimizations. Example from the article:
int square(int x) { return x*x; }
int cube(int x) { return x*x*x; }
int g(int x) { return square(x) + cube(x); }
With inlining, Clang reduces g() to:
mov eax, edi
imul eax, eax
imul edi, eax
add eax, edi
Only two multiplies and one add. Without inlining, you get three multiplies and extra stack manipulation.
Thread Local Storage: Cost Varies by Compiler
On x64, GCC and Clang access TLS via a single indirection through the FS register. MSVC may require up to three indirections. While these are usually cached, they still add overhead.
Thread Context Switches: 10,000-100,000 Cycles
The direct cost of switching threads is ~2,000 cycles, but cache invalidation can add up to 3 million cycles (LiEtAl). This explains why Windows CRITICAL_SECTION defaults to 4,000 spin iterations — burning 15-20K cycles trying to avoid a context switch is worth it.
What This Means for Your Code
- Prefer multiplication over division; avoid division in hot paths.
- Use
dynamic_castsparingly; prefer virtual functions or templates. - Use exceptions for truly exceptional cases (error rate < 0.01%).
- Minimize atomic operations, especially across NUMA nodes.
- Enable inlining aggressively; use LTO to get cross-module visibility.
- Benchmark TLS access if your code runs on MSVC.
- Design for cache-friendly thread affinity to reduce context switch costs.

