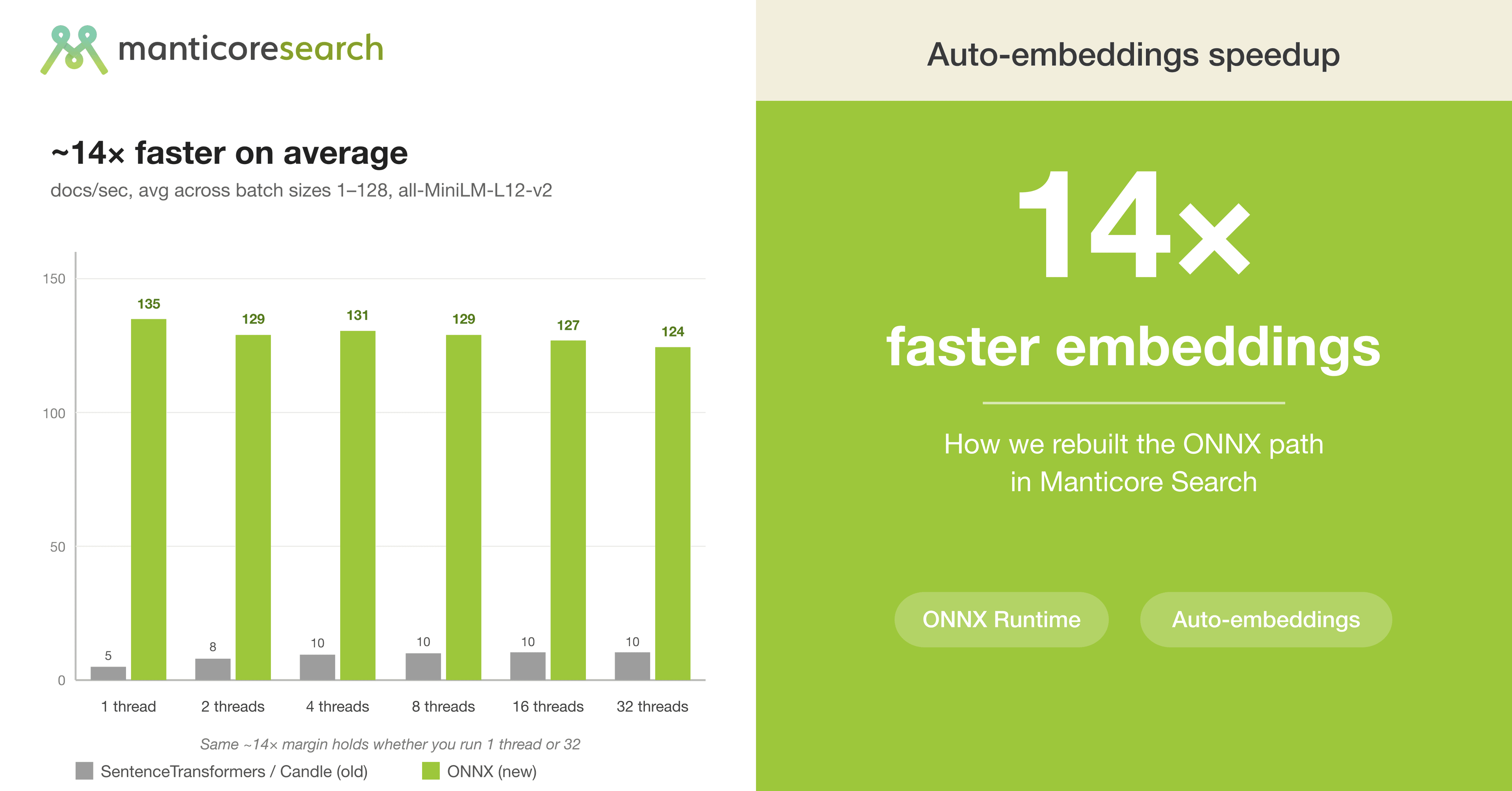
14× Faster Embeddings: How Manticore Rebuilt the ONNX Path
Manticore Search 27.1.5 ships a new ONNX Runtime backend for auto-embeddings that delivers ~14× the throughput of the previous SentenceTransformers/Candle path. On a 16-core/32-thread server with all-MiniLM-L12-v2, the old path managed 5–11 docs/sec across all thread and batch configurations. The new path lives in the 70–230 docs/sec range.
Why ONNX Runtime?
The old Candle path (Hugging Face's pure-Rust inference) left CPU on the floor: workloads sat in low-double-digit docs/sec, and concurrent calls serialised on a single model session. ONNX Runtime (ORT) — Microsoft's hand-tuned C++ inference engine — does graph fusion, constant folding, and kernel autotuning. Most popular embedding models (MiniLM, BGE, E5) already publish a pre-fused model.onnx in their HuggingFace directory.
The Session Sharing Hack
The key insight: ORT's C Run() API is thread-safe on Linux and macOS. The Rust wrapper hides this behind borrow-checker rules. Manticore wraps the session in an UnsafeCell and implements Sync/Send manually:
#[cfg(not(target_os = "windows"))]
struct SessionWrapper {
inner: std::cell::UnsafeCell,
}
#[cfg(not(target_os = "windows"))]
unsafe impl Sync for SessionWrapper {}
#[cfg(not(target_os = "windows"))]
unsafe impl Send for SessionWrapper {}
impl SessionWrapper {
fn with_session(&self, f: impl FnOnce(&mut Session) -> R) -> R {
f(unsafe { &mut *self.inner.get() })
}
}
This single shared session eliminates lock contention and pool overhead. On Windows, a Mutex serialises access due to known ORT threading issues.
Batching Was a Trap
Textbook advice says batch inputs for throughput. Manticore tried batching 8, 16, 32 documents per inference call — and got lower throughput than processing one at a time. Two reasons:
-
Padding tax: A batch of mixed-length texts pads every row to the longest. Real inputs vary wildly: one 60-token outlier forces seven 8-token rows to pay for padding. The model does work proportional to
batch_size * max_len * hidden_dim, most of it on padding. -
Spinning: ORT's intra-op thread pool defaults to busy-waiting between dispatches. With one big batch, threads stay busy. With many concurrent small calls, every worker's pool pins cores at 100% CPU — stealing resources from tokenizers, HNSW builds, and the rest of
searchd. Flippingwith_intra_op_spinning(false)immediately raised throughput and dropped CPU usage.
The Final Design
- One shared session, no pool.
- One document per inference call, no batching inside the worker.
- Many concurrent callers, scaled to CPU count.
- No spinning between calls — yield the CPU.
The predict_pipelined function has two branches:
fn predict_pipelined(&self, texts: &[&str]) -> Result>, _> {
let bs = batch_size();
if texts.len() <= bs {
// Fast path: single tokenize + infer, no thread overhead
return Self::tokenize_and_infer(&self.session, &self.tokenizer, texts, ...);
}
// Large input: split across workers, each running 1-doc-at-a-time
// through the SHARED session
let num_workers = (texts.len() / bs).min(available_cpus()).max(1);
let docs_per_worker = texts.len().div_ceil(num_workers);
std::thread::scope(|s| {
for worker_texts in texts.chunks(docs_per_worker) {
s.spawn(move || {
for text in worker_texts {
Self::tokenize_and_infer(&session, &tokenizer,
std::slice::from_ref(text), ...)?;
}
Ok(())
});
}
});
// ...
}
Single-row INSERTs take the fast path with zero coordination overhead. Bulk REPLACE INTO takes the parallel branch.
Performance Numbers
All runs on a 16-core/32-thread server with all-MiniLM-L12-v2-onnx, 1000 documents per run.
| Configuration | Old Candle (docs/sec) | New ONNX (docs/sec) |
|---|---|---|
| 1 thread, batch=1 | 5 | 72 |
| 1 thread, batch=64 | 11 | 233 |
| 8 threads, batch=1 | 8 | 130 |
| 32 threads, batch=1 | 8 | 100 |
Single-insert latency: ~14 ms with one client, ~56 ms under 8-way concurrent load (vs 200+ ms for Candle).
What Changed (and What Didn't)
No user-facing API changes. Tables pointing at an ONNX-capable model pick up the new path automatically. To switch models without recreating a table: add a new column with the new model, rebuild embeddings, drop the old column.
The two biggest performance wins: with_intra_op_spinning(false) and giving up on batching documents inside the worker. The reverted commit 980b24b marks the moment the team stopped fighting the profiler.
Why This Matters for Developers
Auto-embeddings run the model on every INSERT — embedding speed is ingest speed. The old path capped throughput at 5–11 docs/sec regardless of hardware. The new path raises the floor to 70+ docs/sec and gives meaningful tuning options (batch size, thread count). For bulk indexing, peak throughput hit 233 docs/sec on a single client thread with batch=64.
Manticore Search 27.1.5 is available now. If you're using auto-embeddings, upgrade and watch your INSERT throughput jump an order of magnitude.




